
Last week, two small white fixtures, each a bit bigger than a human head and looking like an upside-down stack of Tupperware bowls, were mounted on lightpoles at Damen and Cermak and Damen and Archer. Inside the fixtures are environmental sensors, designed to measure air quality, weather conditions, light, vibration, and magnetic fields, plus a microphone for detecting decibel levels and a camera capturing still frames. (A Bluetooth modem that caused some concern a while back has been scrapped.) Small Linux-based computers process the data and pass it on to Argonne National Laboratory.
If you haven't seen them, you will. By the end of the year the Array of Things will consist of 80 nodes (fixtures) in Chicago; by the end of 2018, 500. Chattanooga, Atlanta, and Seattle, and Bristol and Newcastle in the United Kingdom will begin installing identical pods this year, and next year Boston, Austin, Delhi, Singapore, and other cities will start to build their own arrays, an open-source network generating public data all over the world.
That, in short, is what the Array of Things does. But what do we do with it?
To answer that, zoom back in on the first 42 nodes, going up right now.
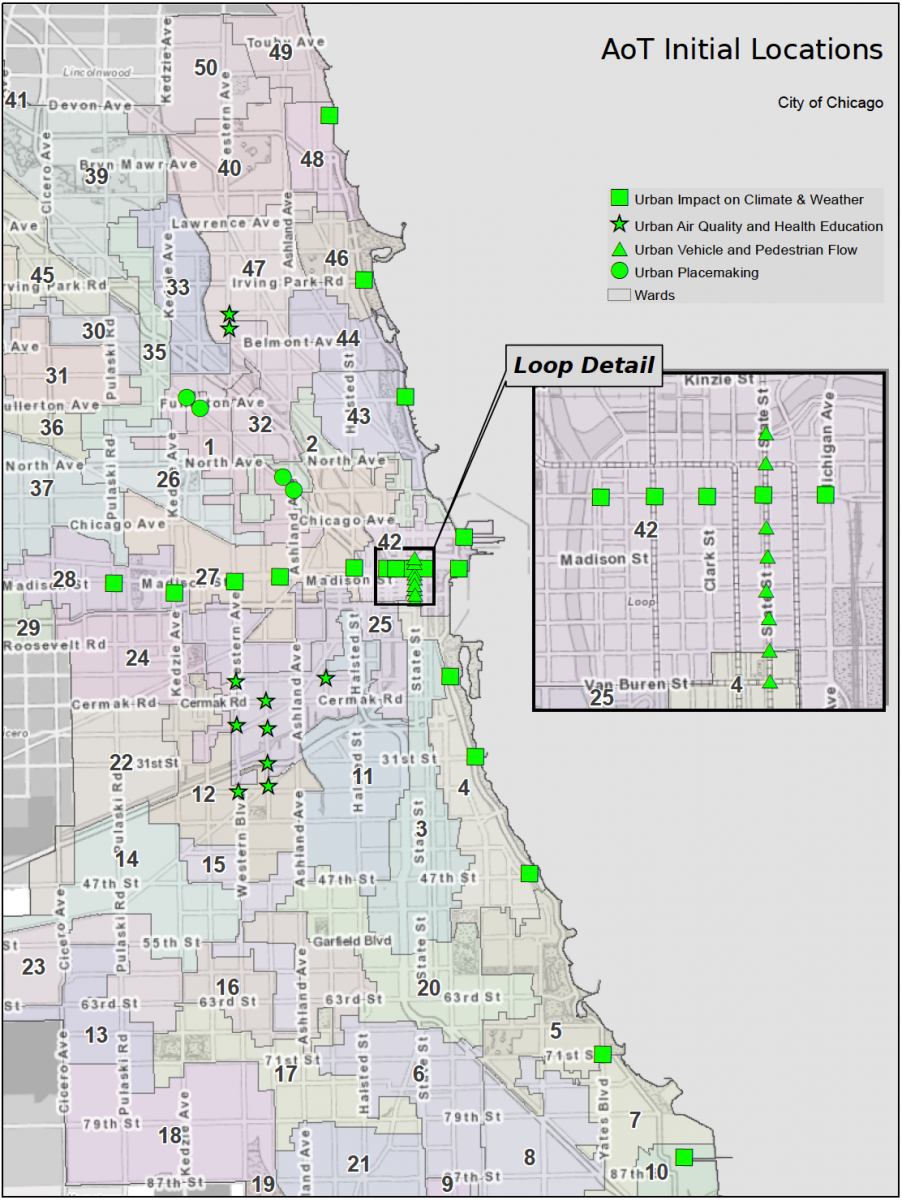
The first two nodes to go in are part of a cluster in Pilsen. "The Pilsen neighborhood is a good example," says Charlie Catlett, director of the Urban Center for Computation and Data at the University of Chicago, a senior computer scientist at Argonne, former chief technology officer of the National Center for Supercomputing Applications, and director of the Array of Things project. "There were people that lived there that contacted us, there were hospitals there that contacted us, the city was interested in air quality on the West Side, groups like the Center for Neighborhood Technology were interested, and there are scientists at the University of Chicago that are studying asthma there and on the West Side. So there was a confluence of interests. In Pilsen there's also the Instituto del Progreso Latino, that's a charter high school with a focus on health-care careers. This coming together on the West Side told us that probably the best way to look at placement of the next 450 or so nodes is to start with something that's of interest to the residents, and then see if there's a science community that's also interested in looking at data that would be related to that opportunity or that challenge or concern."
Chicago has one of the worst problems with asthma mortality rates in the country, and its prevalence varies greatly by neighborhood. The Pilsen nodes will straddle the Stevenson Expressway with particulate sensors, which can detect anything from fine particulate matter, so small that it moves by electrostatics instead of air, to pollen.
"We'll be able to ask questions like, how does the air quality in Pilsen change when the Stevenson Expressway is at rush hour? How long does the rush hour effect on air quality—if there are some effects, which we think there probably are—how long does that linger after rush hour? How far into the neighborhood does it go?" Catlett says. "So you could look at the different flow rates as they distribute across the city, and start to get some understanding of what you might be able to do in terms of green spaces, or other construction, or traffic patterns, to reduce the concentration of those particles in certain parts of the city."
A second set of the initial nodes forms a T-shape, with one arm running along Lake Shore Drive and the other west along Randolph Street from the lake to Pulaski Road. That will allow the array to capture the impact of the lake on air quality and weather patterns. A third set, densely packed along State Street, will compare the array's traffic-counting capabilities to an existing commercial provider. Finally, small clusters on Milwaukee will look at car-bike-pedestrian interactions at intersections where they come in conflict often.
Those last two are where the capabilities of the nodes' cameras—an issue of concern that's arisen—come in.
"We looked at the map of high-traffic-accident intersections and corridors that the Department of Transportation has as part of their Vision Zero program to eliminate traffic-related fatalities by 2022," Catlett says. "So in the next round, after this one, we're hoping we catch a number of their high-traffic-accident intersections and corridors as well. The idea there is to see if we can use these sensors and cameras not to just detect that an accident happened, but to move, over the next few years, as the technology improves, to the point where we might start to produce measurements of near misses."
Instead of capturing video, the cameras will capture still images at a rate of one or two per second. The small computers on board each node then process those images, extract whatever data researchers have specified—how many cars passed through an intersection, or how many heavy trucks did, or pedestrians—turn it into numbers, pass those numbers from the node computers to the database at Argonne, and delete the images after giving the computers a few minutes to process them.
The cameras are somewhat limited in the level of detail they can capture; Catlett says that, from what he's seen, they're not detailed enough for a researcher looking at them to be able to read a license plate or recognize someone's face.
"As an example, here's one we'd like to do but I don't know if we have enough power in the nodes to do it. I noticed when talking with Vision Zero people that one thing they were looking at in fatalities was the use of protective equipment," Catlett says. "In the case of a bicyclist, the question is, how many of our bicyclists are wearing helmets? If I wanted to detect the number of bicycles that goes through the scene per minute, and the percentage of those that were wearing helmets, then I'm essentially reporting two numbers every minute … 20 bicycles, 12 wearing helmets. I extract that from the images, report the numbers 20 and 12, and then I delete the image."
The nodes can also be instructed to look for standing water and ice.
"One of the things we're hoping to be able to help city departments with is where we have poor street conditions," says Brenna Berman, the city's chief information officer. "When it rains, we know we have flooding in Chicago, and we certainly get 311 calls when that flooding is in your basement, but you probably wouldn't think to call 311 when you're two blocks away from your house and there's a larger than normal puddle. We care about that because that's an indication of a backup in our water system."
The nodes have limited storage; they don't create and store an ongoing visual street view or transmit one back to the database, and the Array is treated like a research instrument.
"Imagine that you're a researcher at Arizona State University, and you've developed this algorithm for counting bikes and determining whether [cyclists] have helmets on," Catlett says. "Then you would write a short proposal that would go to our scientific review team, saying what you wanted to do, and telling us you just want to collect those two things, and assuring us that you're also not looking for your ex-girlfriend or something. We would then review the algorithm and install it on one or more nodes and test it out, and see how it performed. If it turned out to be scientifically useful, we'd start publishing that data, along with all the other open data, and then we'd update list of what we're extracting from the images."
So a government department could not, for example, seek out past footage the way it can from a security camera; the AoT nodes have to be programmed in advance to extract specific information, a process overseen by the University of Chicago.
"If somebody were to come and ask for any of the data, we have already a policy—the data is owned and copyrighted by the University of Chicago. The University of Chicago is the only organization that actually controls the data," Catlett says. "Everyone else, including Argonne National Laboratory and the city of Chicago, are essentially subscribers to that data. If there's a user at Argonne that wants to analyze the data, they become a subscriber of that data. If there's somebody in the Department of Transportation they subscribe to the data—they sign an agreement for how that data can be used. At the University, we already have this policy, because we run hospitals and have PII [Personally Identifiable Information, categorized on the AoT's privacy policy] that's much more sensitive than you could get off of this instrument, there's a policy that we would go to, and those kind of requests would go to our legal department."
Air quality, road conditions, and pedestrian/vehicle traffic counts are among the first things the Array of Things will measure. A microphone, which detects noise level changes but does not record audio, can be used to address quality-of-life concerns from emergency vehicles, nightlife, or heavy vehicles. Heavy-truck traffic is likely to be an early focus; the sensors include a magnetometer that, Catlett thinks, may be able to determine the presence of large vehicles by their impact on the magnetic field surrounding the node. (If not, cameras and an accelerometer can be used to detect them.)
"There are already rules in place around where heavy vehicles can and can't go in the city, but that's particularly hard to enforce," Berman says. "Heavy vehicles create a disproportionate share of the wear and tear on our roads. Being able to understand where those vehicles are traversing the city helps us better plan for road maintenance, perhaps change some of our enforcement around how we manage heavy truck traffic, and just give us information on how heavy vehicles are making their way through the city."
Those uses derive pretty logically from the sensor capabilities. But among the scientific communities Catlett and his team sought for potential uses were social scientists, who could have less obvious uses for the data down the line.
"Perhaps for me the most intriguing was the set of conversations we had with social scientists and economists," Catlett says. "You can't go to Radio Shack and buy a neighborhood-cohesion sensor. They deal with second-order effects, or effects you can't measure with a physical sensor.
"We also started to talk about the research that's been done with Google Street View. Even 20 years ago, when Robert Sampson [a Harvard sociologist and author of Great American City: Chicago and the Enduring Neighborhood Effect] was at UChicago doing letter drops, he was also driving around with video and audio, doing Google Street View before there was a Google. Then we were asking the question—what could you detect from an image of a street corner or a park that would tell you something about how people feel about their neighborhood? There were a couple examples—one, if you see a lot of people walking babies and dogs, maybe that's a sign that people feel safe in the neighborhood. If you see a change in the number of groups of people involving kids and adults in the use of the park, maybe that means that families are using the park more, or starting to use the park less. These conversations with the social scientists really got our interest piqued in using machine learning with the images to get a feel for what's happening in the neighborhood beyond what you could just get from using a sensor."
Just as the AoT nodes may be able to tell whether a cyclist is wearing a helmet and turn that visual data into numbers, they could also, Catlett thinks, be programmed to tell whether someone is walking a dog or pushing a stroller. As an example, Catlett cites a software engineer at NVIDIA, a company specializing in graphics processing units, who, faced with neighborhood cats pooping in his lawn, built a system that turns on his lawn sprinklers when a cat is detected. And it is a tidy example of how visual machine learning can, in the hands of a skilled programmer, be done with off-the-shelf parts: he fed a deep learning neural network millions of pictures of cats to "train" it, reaching 90 percent accuracy.
A less trivial example, closer to what social scientists might be able to get out of such data, is the kind of research Catlett mentions with Google Street View. In one instance, a team led by the Harvard economist Edward Glaeser used a similar approach—a machine-learning algorithm—to predict income levels in neighborhoods based on the images Google captured. Their results matched Census data with 77 percent accuracy. Another study used Google Street View images to measure "neighborhood physical disorder," a typical subject matter for sociologists like Sampson, with even greater accuracy.
The applications are potentially broad, which goes a long way to explain its early embrace by other cities, and its funding. The installation and maintenance for all 500 nodes is grant-funded through 2018, the biggest chunk being $3.1 million from the National Science Foundation, with supporting grants from Argonne, the University of Chicago, and the U. of C.'s Chicago Innovation Exchange. According to Berman, the city is working with the NSF for a maintenance grant for the length of the pilot period, about five years.
"Where we go after that is not something we're worried about because of how much technology changes in five years," Berman says. "I think we're going to be pleasantly surprised about the value this data has to us, and we can make decisions about how the program develops as we see that unfold."