

If you’re the type of person who ever contemplates what more you could have done with your life, I have some advice: Don’t talk to Rick Stevens. Just 15 minutes into a conversation with him, I already feel like an idiot. Outwardly, I’m making direct eye contact, taking notes, putting my fingers to my lips to signal I’m hanging on his every word; inwardly, I’m thinking about how many hours I’ve spent on YouTube rewatching clips from The Sopranos.
Stevens is the associate laboratory director for computing, environment, and life sciences at Argonne National Laboratory in southwest suburban Lemont. The title wordily obscures his accomplishments. Stevens, who started computer programming at age 14, has been at Argonne (the country’s first national laboratory, established in 1946 and jointly operated by the U.S. Department of Energy and the University of Chicago) since 1982, when he was still an undergrad at Michigan State. After he joined Argonne, he got a doctorate in computer science at Northwestern. Over the past 40 years, he’s been a key figure in Argonne’s significant advancements in supercomputing.
On a sunny day in November, I’m sitting in Stevens’s office to learn more about the Aurora supercomputer, Argonne’s next big leap in computational speed and power. The lab has been laboring over supercomputers for nearly its entire history, in a constant state of conceptualizing, formulating, fundraising, designing, constructing, testing, and operating. But in a decades-long span of inexorable innovation, Aurora is a unique milestone. When the machine is fully constructed and operational — Argonne officials are hoping for early spring — it will be one of the first supercomputers in the world to operate at exascale, a new and unprecedented stage of computing.
And this is why I came to talk to Stevens. He’s over six feet tall, with fantastic long brown hair hanging past his shoulders, and a wide frame, like he could have played football. On the day I meet him, he’s wearing glasses, Birkenstock sandals with socks, flowy black yoga pants, and a loose-fitting sweatshirt.
The first question I ask him: What’s the impact Aurora will have on our everyday life?
“What’s the impact?” Stevens replies, rhetorically and exhaustedly. “Well, you can get a hint of it, maybe, from the impact that supercomputing has had on the world in the last 20 years. Everything we know about large-scale climate comes from climate simulations on supercomputers. What we know about the human genome comes from massive data analysis on big computers. Everything that’s happening in AI right now is happening on large-scale computers. Just the idea that you could build a system that might be able to drive a car is a result of huge amounts of computing. Our ability to design reactors, our ability to come up with new batteries — all that is a result of computing.”
You know, just the climate, the human genome, nuclear power, robots.
“The exascale machine is the latest version of that,” Stevens continues, “and an exascale machine is a million times faster than the machines we had at the turn of the century.”
Still, how could we witness a “million times faster” empirically? How would we be able to see that materially in our everyday lives? I didn’t want to repeat my initial question, so I ask it in the form of a follow-up: Exascale computing is going to perform functions that we can’t execute now, right?
“Yeah, it’s a million times faster,” Stevens answers, another way of saying, Duh!
Then he does something no one I’ve ever interviewed has done before: He explains to me how I should write my story.
“The gee-whiz reporting on these machines is not super enlightening,” Stevens says. “Reporters like to do it because people have gotten so used to the idea that ‘I have a phone and it talks to a giant cloud and there’s thousands of processors in there,’ and that’s true. The industry has built it over the last 15 years or so. We build these scientific machines because they’re focused on problems in science, whereas clouds are, you know, powering Twitter and Facebook and Discord servers and all kinds of random stuff, fake news and all that.”
Stevens rolls his eyes repeatedly as he delivers this spiel, a wall of thick books about astrophysics and advanced computer science behind him. Then, like the sorcerer in Fantasia conjuring powers beyond the ken of mere mortals, he becomes impassioned.
“You don’t design an airplane without supercomputers. You don’t design an airplane engine without supercomputers. You don’t design a car anymore without a supercomputer. You don’t even design the mixtures in gasoline without a supercomputer. You can probably try to name something, almost anything of value, and it is going to have its roots in some kind of high-end computing simulation or data analysis system.”
I was starting to see what Stevens meant when he dismissed most stories about computers. But because I probably appeared to have the intellect of a small child, he tells me outright: “The real story is you’ve got a community of people that have been working on advancing high-performance computing for decades. And it powers the whole economy.”
I begin to realize he’s frustrated not with me per se but with what computers have come to mean to the general public. Rather than focus on how computers have collectively benefited humanity, the conversation around them tends to center on how they make our lives more convenient. In which case, Stevens is right: This isn’t a story about how Aurora might alter our lives, but how it might change the world.

Before I started learning about Aurora, my understanding of computer history was admittedly reductive. I surmised it was more or less the Turing machine, followed by huge, bulky mechanisms that went zap and boink and clang and were too unwieldy to be used by anyone but government agents, Russian scientists, and IBM employees, followed by PCs and Bill Gates and the internet, then by Steve Jobs and his iPhones, and now I can ask my HomePod to play the BBC while I browse the web on the door of my fridge, and pretty soon robots will do everything for us before we realize we’re living in a giant simulation. Sure, it’s obviously more complicated than that. But is it really?
Of course it really is. The history of computing is vast and multifaceted and complicated with various classes of machines, of which supercomputers are but one. Their story goes back to the 1950s and begins on U.S. soil, when Seymour Cray joined a group of engineers at the Control Data Corporation in Minneapolis to construct the CDC 1604, which debuted in 1960. There’s debate as to whether it was truly the first supercomputer, but what’s indisputable is that it was the fastest computer in the world — and that it sparked a global quest to build ever-faster ones.
In the late 1970s, architects of supercomputers encountered a problem: Their central processing units, or CPUs, had reached a speed of one megahertz, meaning they could cycle through a million functions per second, and computer scientists didn’t think that they could go any faster. The solution was parallel processing — that is, using more and more CPUs to make a computer faster and better.
“It’s kind of like thinking about a brain,” Stevens says. “Your brain only runs at a certain speed. And if I wanted to get more brainpower, I need more brains, not a faster brain.”
Thought of this way, supercomputers aren’t so different from the grotesque science-fiction creations of John Carpenter or Frank Herbert. They’re not quite monstrous, but their enormous complexity can be frighteningly difficult to comprehend. Especially the math.
At this point, Stevens pulls out a marker and walks across his office to a dry erase board. I’m now being treated to one of his lectures (he’s also a professor at the University of Chicago).
“How fast is an individual processor? You have any guess? How fast is the processor on your iPhone?”
“I really don’t know,” I answer, growing a little weary.
“Just make up something. There’s a clock in there. How fast is the clock?”
“Like, how many rotations a second?” I ask, in a tone that is pleading with him to just tell me.
“Well, it doesn’t rotate,” he says, unnecessarily. “But yeah, just make up a number.”
“A million.” Which seems to me a reasonable guess.
“It’s actually a billion.”
There’s a pause of a few seconds that feels like an eternity before he starts writing numbers on the board.
“The basic processor in your iPhone or PC or whatever runs at a gigahertz: a billion cycles per second. Some of them run at five gigahertz, some at two. Your iPhone actually can go anywhere from about one to three gigahertz, but it doesn’t matter — it’s about 10 to the ninth [power]. And we wanted to get to 10 to the 18th operations per second. This is exascale.”
In Argonne literature, this operating speed is referred to as a “billion billion,” which seems like a number so big they have to repeat an existing number twice, but technically it’s a quintillion operations per second, or an exaflop. Here’s a better way to frame it: In my lifetime, computers have gotten a trillion times faster (I’m turning 40 this summer).
Yet back in 2007, no one knew if exascale was even possible. That year, the Department of Energy held town hall meetings at three national laboratories — Argonne, Berkeley, and Oak Ridge — to discuss how its scientists might be able to realize a supercomputer running at this speed.

Along with Stevens, one of the participants in those conversations was his deputy, Mike Papka. Papka met Stevens 30 years ago, when he was studying for a master’s in computer science at the University of Illinois Chicago. He’s been at Argonne ever since (and also earned his doctorate at the University of Chicago). If “Mike Papka” sounds like the name of someone you’d get a beer with at the corner tap, well, that’s exactly what he’s like. His gray hair is trimmed short, he wears thick black-rimmed glasses, and he has a bushy white beard as long as Rick Rubin’s. His conversational style is down to earth and good natured, and he speaks with a Chicago accent as chunky as giardiniera. When I ask him about those DOE town halls 16 years ago, he says they’re “a blur,” but he does recall thinking that “the infrastructure you would have to have for [exascale] is impossible.”
When the DOE’s scientists convened, they faced three particularly daunting obstacles. The first was power. At the time, they estimated that an exascale computer would require 1,000 megawatts of electricity, the equivalent of a nuclear power plant. They decided that the most persuasive case they could make to the government to secure funding would be if they cut that down to 20 megawatts. If slicing 980 megawatts seems extreme, Papka points out that setting ambitious goals helps achieve maximum progress. “You have to do a tradeoff,” he says. “Are we going to wait 15 more years to figure out how to get technology there? Or are we going to proceed?”
The next issue was reliability. Just like your laptop, supercomputers are susceptible to crashing when they get overheated (which would happen often with a machine that requires as much electrical power as a small factory). The DOE crew set a goal of limiting an exascale machine’s crashes to one a day, which still seems like a lot. But Stevens explains that the supercomputer doesn’t lose all its work. “What happens is that you are constantly taking snapshots when the machine crashes so that you can restore and keep going,” he says. “It’s like on a computer game — people get killed and you just reboot and the game starts over from where you left off.”
Aurora is like the world’s most complex symphony, with hundreds of thousands of different instruments playing in unison to keep the music going.
The biggest problem of all was scale, though not of what you’d probably guess. Sure, supercomputers are physically huge, but it’s what’s inside the machine that seemed the most difficult to figure out.
“On the hardware side, no big deal, because you just can add more hardware,” Stevens says. “But on the software side, a big deal. Think of it this way: You’re making Thanksgiving dinner, and you’re cooking all these dishes in parallel. And the amount of time it’s going to take to cook the meal is determined by the slowest step [the turkey], even if the pies only take one hour, or if the vegetables could cook in 30 minutes. So think of that same problem in these computations, except instead of having 20 things in Thanksgiving, we’ve got a million things, and now I’ve gotta have a billion things going on in parallel. And how fast this is, is going to be determined by the longest step, which means I have to make that longest step as fast as possible.”
On top of its complexity, supercomputer software is expensive. The science world doesn’t function like the tech companies in Silicon Valley; there’s no such thing as startup culture, where venture capitalists might finance R&D on a moonshot project. For scientists, it isn’t easy to get funded.
Between 2007 and 2015, all the work on exascale computing was research and development — problem-solving and writing algorithms to construct the least obtrusive, least expensive supercomputer possible. While Aurora itself wound up costing $500 million, the tab for the entire Exascale Computing Project — the collaborative effort between the national labs — would total far more. And to secure that funding, the scientists had to demonstrate they could make exascale work.
“It’s not easy to ask for $5 billion,” Stevens deadpans. “I mean, it’s easy to ask. But the government’s not going to write you a $5 billion check if you say, ‘I don’t know.’ The team’s got to say, ‘OK, we have a way we think we can do this. We’ve done experiments, we’ve got the error bars down,’ and so on.”
Just the process of asking was challenging in itself. When scientists first had discussions with the DOE about exascale computing, George W. Bush was president. Since then, there have been three other administrations, with sundry secretaries of energy and, to put it lightly, very different agendas. “You’re making the same argument over and over and over as the government has changed and trying to reeducate everybody,” Stevens says. “So you had to kind of work all of these issues, keep building a plan, building a new plan, building a better plan, selling it. It took a huge amount of effort.”
Once the Argonne scientists were ready to start actually developing Aurora in 2015, they had to manage that process as well, coordinating with Intel and Hewlett Packard Enterprise, which manufactured the software and hardware. “It was like going to Mars,” Stevens says. “What you’re seeing now is just the iceberg sticking out of the water. Yeah, we got a machine. But you don’t see the 90 percent of the effort that happened before it.”
It’s very loud in here,” David Martin says just outside the doorway of Argonne’s data center, which houses all of the lab’s supercomputers. When we’re inside, it sounds like we’re standing in the world’s largest air conditioner; we have to shout in order to hear each other. Martin is the manager of industry partnerships and outreach, which means he coordinates with third parties — usually companies like General Electric, General Motors, and Boeing — on how to access and use Argonne’s supercomputers for research. Before starting here in 2011, he did stints at IBM, Fermilab, and AT&T Bell Laboratories.
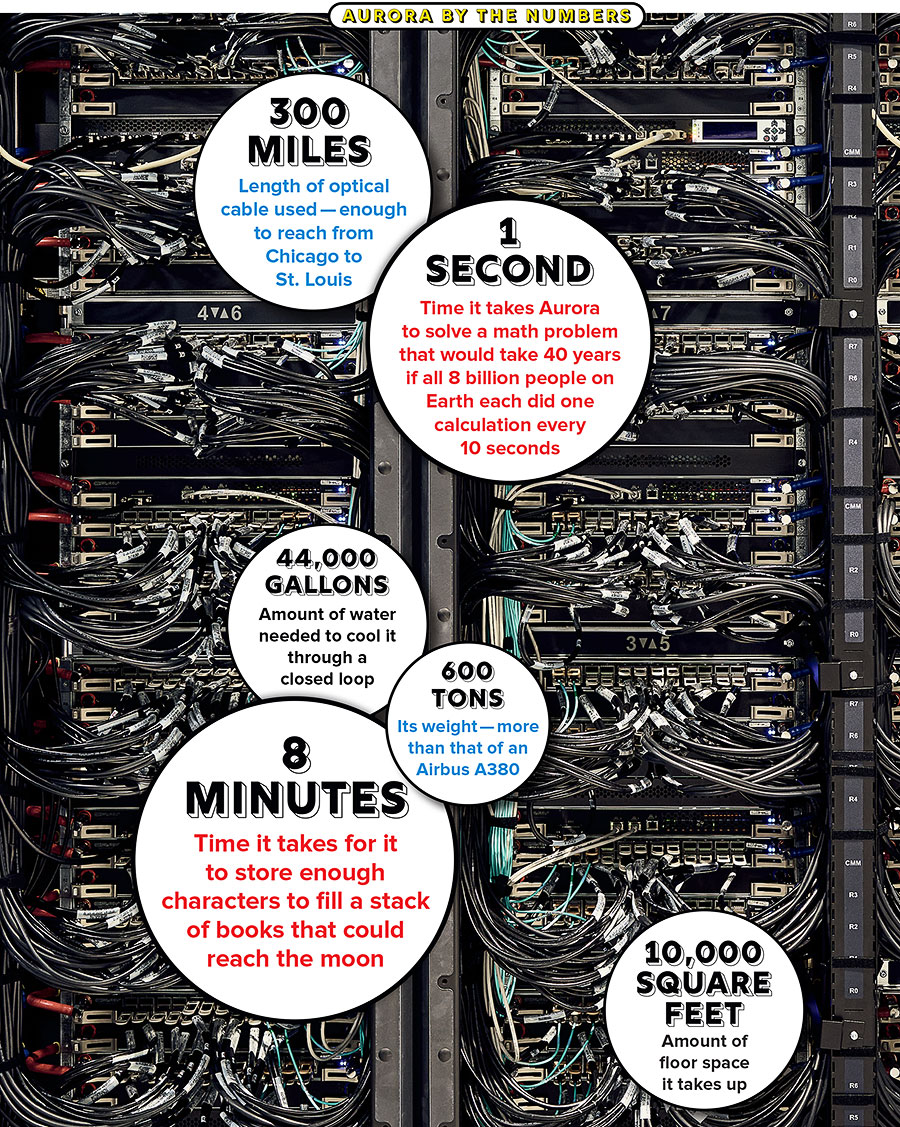
Argonne constructed the data center and the infrastructure supporting it, essentially an entirely new building, in order to accommodate its supercomputers. The actual machines are in the “machine room.” Aurora is roughly as big as two basketball courts — about 10,000 square feet — and around eight feet high. Argonne added a whole new wing to the machine room for it. What takes up the most space, though, is not the supercomputer itself but the utilities needed to keep it operational.

Above Aurora is an entire floor, called the electrical room, devoted to powering the supercomputer. The space is as big as an airplane hangar and contains clusters of metal stations that look like enormous breaker boxes and can produce up to 60 megawatts of electricity, enough to power more than 10,000 homes. Papka emphasizes that 60 megawatts is the absolute limit — Aurora will more likely run at around 50 to 54 megawatts, if that. “Our old system, Mira, had a peak of nine megawatts,” Papka says. “But if I’d look at the electric bill, it was more around three and a half. So if you target for peak — everything’s perfect, you’re using every piece of silicon on that chip — you’re gonna consume all that power. But you never get there.”
It’s important to keep in mind that this room also fuels the existing supercomputers at Argonne, including the petascale Polaris, and provides all the electricity in the building. Considering that in 2007 the scientists at those DOE town halls were worried that an exascale computer would require 1,000 megawatts of power, eliminating 940 is a staggering achievement.
But the real innovation is on the floor below Aurora: the mechanical bridge. Here, labyrinthine pipes of varying widths worm around a room, delivering, cooling, and filtering water. Supercomputers have used liquid cooling for a long time (Papka recalls a Cray machine in the early ’90s that used oil as a coolant), but to reduce plumbing costs, Argonne has increasingly relied on fans to prevent overheating. As no fan is powerful enough to keep newer supercomputers cool, scientists have had to create more efficient water-cooling systems. It isn’t all that different from the ways radiated floors prevent your feet from getting cold in fancy bathrooms, except this is a much more sophisticated bathroom.
Polaris is temperature controlled with a combination of water below it and jet fans above it — hence the loud noise in the data center. When Polaris is inevitably decommissioned, the fan noise will cease, replaced by what Martin describes as “a hum.” It’s doubtful that there will be another supercomputer predominantly cooled by fans. “From the standpoint of a lab being responsible environmental citizens, what’s nice about water is it’s water,” Papka says. “It’s got one of the best coefficients for moving heat of any substance.”
The machine room holds both Aurora and Polaris and will likely be where all supercomputers remain for the foreseeable future. It’s about the size of a football field, with fluorescent overhead lights similar to those in a standard office building. On the floor is a grid of square gray tiles, each about the size of an extra-large pizza box. The tiles are removable so that construction workers can access the pipes in the mechanical room through the floor, allowing the workers to isolate and fix specific pipes without damaging anything else in the process.
On the day I’m at Argonne, a construction crew of around two dozen is busily working on Aurora. The initial estimated completion date for the supercomputer was 2020, but supply chain issues caused by the COVID-19 pandemic extended the timeline. I’m not allowed to enter the construction site, but I spot what look like rows and rows of black cabinets. In the end, Aurora will resemble an even bigger version of the massive computer servers you’ve seen in high-tech spy movies like Skyfall or, perhaps most accurately, Michael Mann’s Blackhat.
Outside the machine room is a long hallway and window that afford visitors a wide-angle view of Aurora. From here, Martin shows me the nodes that form the supercomputer’s building blocks. These nodes resemble what your laptop looks like under the keyboard surface — an array of chips and dots and metal bars. The tiny white tubes snaking around one side of them are used to cool the processors. “These big 24-inch pipes that start down the road at a chilling plant, cold water comes down them,” Papka says, “and then that big pipe feeds a little pipe, which feeds a littler pipe, which feeds a littler pipe, which gets to the processor.” Aurora is like the world’s most complex symphony, with hundreds of thousands of different instruments playing in unison to keep the music going.

The supercomputer is just rows and rows of these nodes stacked on top of each other, with blue and red tubes looping out of each panel to provide electricity and cooling. Those construction workers are in the final stages of slotting in each node and wiring them as they are gradually shipped by Intel. Aurora’s nodes rely primarily on graphics processing units, or GPUs, rather than the CPUs that supercomputers operated on in the past. GPUs are the same processors used in designing video games and special effects in movies.
“People realized that GPUs actually do calculations really quickly,” Martin explains. “And so we worked with Intel to help design the GPUs — they took out the graphics-rendering engine and all the ray tracing and put in more ability to do calculations. So these GPUs are calculation accelerators.” Papka dates this supercomputer innovation to the late ’90s: “The entire world needs to thank the 14-year-olds for their love of gaming, because that’s largely what drove it.”
Aurora’s GPUs aren’t just the future of supercomputers — they’re also the future of personal computers. Eventually, Intel will be equipping all of its PCs with these new processors. In that way, supercomputers are a bit like time machines. “These shared resources the government builds give us a glimpse of the future,” Stevens says. “The scientific community gets to experiment on what’s going to be easily available to everybody five or 10 years later.”
So imagine how fast your PC will be a decade from now with one of these souped-up GPUs. Aurora has six GPUs in each node, and 10,000 nodes, which means, this year, it will run at 60,000 times the speed of your future computer.

How does all that speed and power translate into solving real-world problems? Or, as Argonne employees prefer to phrase it: What problems will Aurora not be able to address? Scientists working on exascale say they think Aurora and supercomputers like it will help us create new and better medicine, improve engineering, alleviate climate change, and even increase our understanding of the mysteries of the universe. But how exactly can one machine do all that? You can’t just ask Aurora how to cure cancer and it tells you, right?
The shortest possible answer is simulations. Most of the discoveries scientists make nowadays happen through a supercomputer simulation of real-world situations. “It’s not that different from how we do climate modeling,” Stevens says. “We have satellites that can measure clouds and temperature. We can do all kinds of things to collect data about the current state of the atmosphere, and we have that data going back for many years. But in order to actually test a theory, like how sensitive the climate system is to changes in methane or carbon dioxide, you have to do a simulation. You can’t go out there and clone the earth and say, Let’s change the atmospheric composition and try to study it.”
When I ask for an example of supercomputer simulations having real-world effects, Argonne employees point to car safety. Remember those old television commercials in which you’d see a slow-motion video of a car with crash-test dummies inside slamming into a stone wall at high speed? Well, that’s still the way that automakers test safety. But crashing cars is expensive, and the companies are always looking for ways to cut costs while improving protection. By running supercomputer simulations first, automakers can plot and tweak multiple scenarios before they have to physically crash a car. In some instances, that makes the difference between building and obliterating a single car and dozens of them.
In one room at the lab, Rao Kotamarthi, the chief scientist of Argonne’s environmental science division, shows me various computer models on projector screens. One is of the East River slowly flooding Manhattan. “This is done for a power company,” Kotamarthi says matter-of-factly. “So we are trying to look at a once-in-a-50-year flood in the future. They are trying to look at whether their facilities are secure in a climate change scenario. We developed this as a portal: You can pick a city or location and get a kind of impact analysis on temperatures. And local communities can plan for resilience.” Kotamarthi uses the 2011 Fukushima nuclear meltdown as an example. Supercomputers won’t be able to prevent natural disasters like the earthquake and tsunami that damaged the Japanese nuclear power plant, but the machines might be able to help energy facilities develop protective infrastructure so that humanity can coexist with the effects of climate change.
You can’t do that on a standard computer. Well, technically, you could, but you’d never want to. “Say I wanted to calculate a star exploding or the evolution of the universe,” Papka says. “Can I do that on my laptop? Yeah, I could write some code. But my simulation isn’t as accurate.” Then comes the kicker. “And it takes seven lifetimes to calculate.”
Katherine Riley, the director of science for the Argonne Leadership Computing Facility, uses astrophysics as an example of what a supercomputer like Aurora can achieve: “We’re all taught in school that you’ve got an atom, and it’s got your protons and neutrons and electrons around it. But we know it’s more complicated than that. We know that there’s a lot more to matter, let alone to that particular atom — there’s subatomic particles. So what that means is understanding how matter was formed. You can build accelerators, and what happens with those accelerators is you generate huge amounts of data and pull out that signal from all of the noise. You create a model of the universe; you create a model of a supernova and you let it burn. And you try to correlate that with what’s actually happening in the real universe.” Riley anticipates that Aurora, purely based on the volume of data it will be able to process, will be able to produce much more sophisticated models.
Scientists have already been doing this for many years. The most prominent example is the James Webb Space Telescope, which has provided images of the deep cosmos in far more vivid detail than its predecessor, the Hubble Space Telescope, giving us a greater understanding of the texture of the universe. The Webb telescope and its corresponding images are all the result of simulations on a supercomputer.
Even though exascale computing augurs a whole new frontier of computational speed, one that’s a thousand times faster than the current petascale supercomputers, that doesn’t mean we will suddenly be able to solve all our climate or engineering problems or discover the origin and history of the universe. Riley is quick to point out that in science there are no answers, only partial answers. And 20 more questions.
What’s changing is how quickly we’re getting the partial answers and new questions. When you think back on all the technological innovation in our lifetimes, and how much it’s accelerated with each passing year, that rate roughly corresponds to the perpetually rising speed and skill with which we develop computers. Martin also points out that exascale computing is going to be much more dependent on AI, which will in turn help train computers to improve functions without human interference. It’s not entirely unreasonable that one day we’ll get to a point where the supercomputers are the ones building better versions of themselves.
At the end of my time with Stevens, his dry erase board is crammed with numbers and charts and equations. We’re both looking at it quietly, a bit stunned, but for him it’s only a tiny fraction of the mathematical effort that went into developing Aurora. And Aurora isn’t the first exascale computer — the Oak Ridge National Laboratory, just outside Knoxville, Tennessee, launched Frontier, a machine powered by AMD’s technology rather than Intel’s, last May. (As for which is faster, we won’t know until Aurora’s debut.)
The first serious conversations around exascale took place 16 years ago, so I ask Stevens if DOE scientists have started working on the next stages in supercomputers: zettascale (10 to the 21st power) and yottascale (10 to the 24th). He says discussions have indeed begun, but he doubts either is achievable within the existing architecture of supercomputers. The challenges are colossal. The facility for storing a zettascale supercomputer would need to be 50 million square feet, and the annual electric bill would be half a billion dollars. I point out that Stevens and his colleagues initially had similar concerns about exascale, but he explains the problem isn’t just that we can’t get that big; it’s also that we can’t get that small.
The transistors that fill each chip in Aurora are seven nanometers, a comically microscopic figure equivalent to 70 atoms placed side by side. Building transistors the width of one atom — as small as you can get — is unrealistic at this moment, so the only option is subnanometer lithography. For that reason, President Joe Biden’s CHIPS and Science Act, signed into law last August, is critical for the future development of supercomputers, since funding microchip R&D is integral to maintaining the country’s rate of technological innovation. But even so, Stevens thinks, we’re a long way from zettascale: “They’ll try to get that small, but they’re actually not going to get this small, at least in the next 10 years. I think we’re at about the limit.” When I ask Papka what he thinks, he says, “I’m gonna be retired on a beach somewhere, not worrying about this.”
Supercomputers like Aurora are a bit like time machines. “These shared resources the government builds give us a glimpse of the future,” Stevens says. “The scientific community gets to experiment on what’s going to be easily available to everybody five or 10 years later.”
There’s also quantum computing, which in theory would allow for exponentially faster data processing, thereby raising the question of whether supercomputers would be rendered unnecessary. But Papka considers that unlikely. “Supercomputers help us answer questions,” he says, “and if our supercomputers become obsolete, you’d have to tell me that we have no more questions, that we’ve solved every problem there is in the world. And while we may be egotistical, I don’t think that’s ever going to be true.”
More likely, he predicts, there will be an advent of quantum accelerators working in harmony with traditional computers, similar to how GPUs were repurposed to make supercomputers faster. But this is getting into heady territory. Papka throws his hands up when he says, “Talking about the speed at which things are happening, I can’t even keep up.” And as progress is made in quantum computing — Argonne is doing R&D of its own — there will still be plenty of people working on creating faster and more efficient supercomputers.
For Stevens, that happens with a group many of us disparage: Gen Z. “I was young when I started working on this and I’m not young anymore,” he says. “We need to get young people working on this so that we’ve got decades of progress. The amount of training and education that people need to make contributions to supercomputing is huge. These are PhD students, plus postdocs, plus years of training.”
This comment makes me reflect on how computers have shaped my own life. I still remember the day in the early ’90s when my dad brought home our first Apple Macintosh — and the look on his face the very next day when I inadvertently dragged the hard drive into the trash, foreshadowing my prospects as a computer programmer. The only other time I saw him make that face was when our aquarium broke and every fish in it died.
The most significant nonhuman relationships of my life have been with computers. I’ve spent most of my time on this earth in front of a screen, whether reading, writing, talking to other people, or — and this is critical — distracting myself. I wonder to what degree my life might have changed course if I’d viewed computers differently in my childhood and adolescence. During the past few years, I, like many other people, have bemoaned the consuming of social media as a mammoth waste of time, something I turn to for a perverse kind of solace but that only makes me feel gross and bitter and hollow.
In that respect, scientific computing isn’t just the avenue to technological solutions and a better understanding of our universe. It’s also a source of potential, a way of reorienting our worldview to see computers as agents of health and peaceful coexistence. Perhaps that’s overly sentimental, but raw sentimentality might be a better option than the bloodless, ultracorporate rabbit holes of Web 2.0.
Before any of that, though, Argonne still has to power up Aurora — and scientists don’t know for sure what will happen when they do. Parts of the $500 million supercomputer may not even work. That doesn’t mean they junk it and start over — it will only need some tweaks. “We’re kind of serial number 1 of this supercomputer,” Martin says. “If something goes wrong, that extends [the launch] a week, a month, maybe more.”
The strategy is to start running Aurora in pieces. On the day I’m at Argonne, Martin says they’ve already encountered problems after turning on two racks for stress testing. A month after that, when I follow up with Papka, he mentions they’ve ironed out some of those kinks, and scientists have already started accessing those racks to familiarize themselves with the system. But he emphasizes that Aurora’s full capabilities won’t be totally understood for some time. “You put 60,000 GPUs together, well, nobody’s ever done that before,” he says. “How does the software behave? Till you have it, you can’t even begin to figure it out.”
There are still so many unknowns. All we know now is that it will be the future.